OBJECTIVE:
This article is meant to explain the steps that needs to be followed for assigning ingestion jobs to run in a specific tier of middleManager nodes based on worker category in cloud (AWS or GCP or Azure) where the IP addresses of nodes change when they restart.
ENVIRONMENT:
Imply-4.x and above in AWS / GCP / Azure
ADDITIONAL INFORMATION:
Using Affinity (instead of worker category) for assigning ingestion jobs to run in a specific tier of middleManager nodes is helpful if we have static IP addresses for middleManager nodes (usually in self hosted environments).
But in the cloud , we have static IP addresses for master nodes (where coordinator, overlord and ZK are running) and we have dynamic IP addresses for data nodes (where historical and middleManager are running) and query nodes (where router, broker and pivot are running), which can change when a data node or query node gets restarted.
Hence we cannot use affinity to assign ingestion jobs to a certain tier of middleManager nodes in the cloud. Instead we have to follow the below procedure based on worker category.
PROCEDURE:
The following steps are needed to enable worker category for a data tier of middleManager nodes :
1 - Create new data tier with desired number of data nodes.
2 - Put load rules on existing data sources for every data source so that the segments of each data source will go to the desired tier
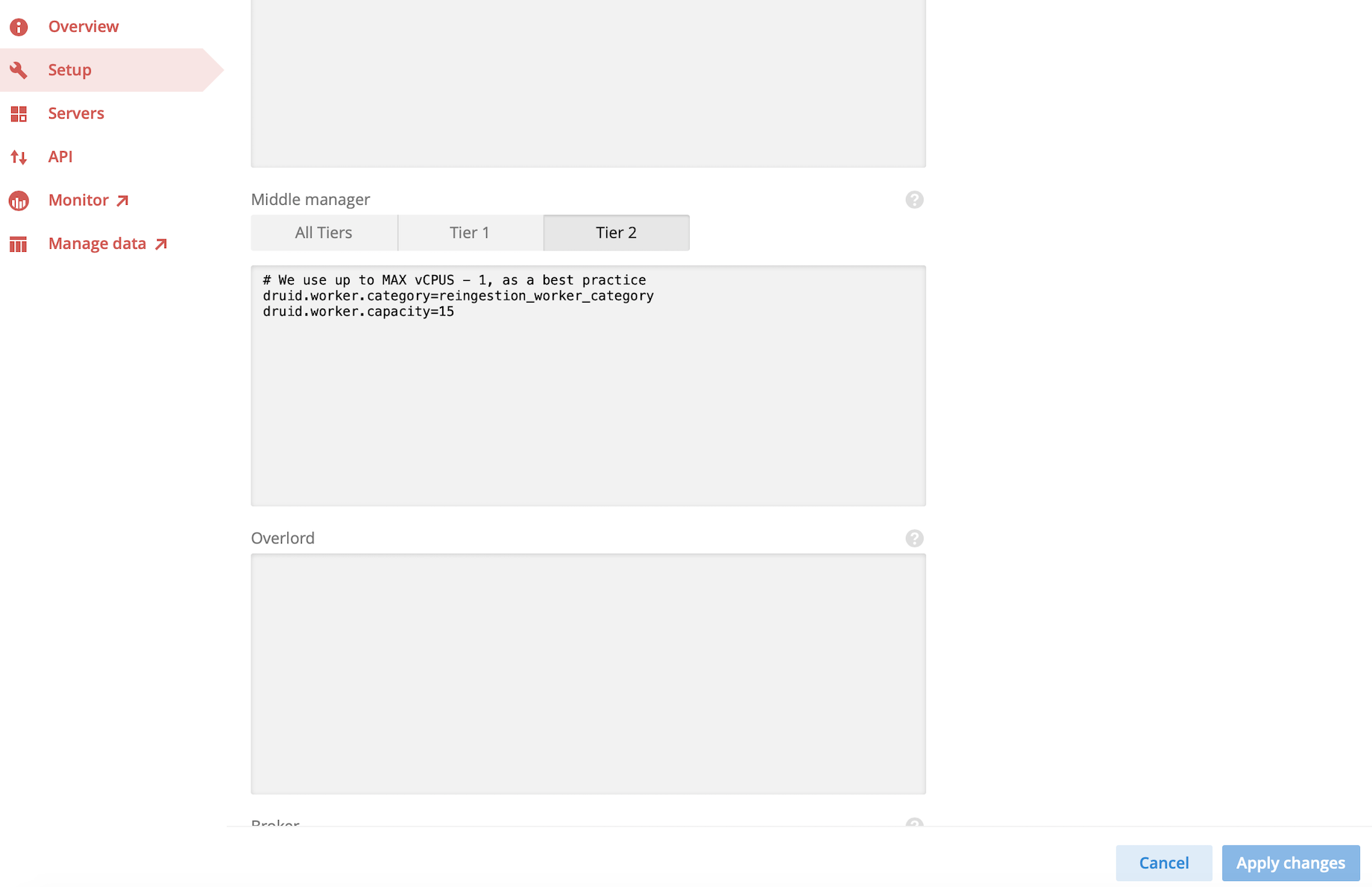
3 - Go to Set up -> middleManager runtime override section.
Declare druid.worker.category and druid.worker.capacity for the new tier (in this example - tier2)
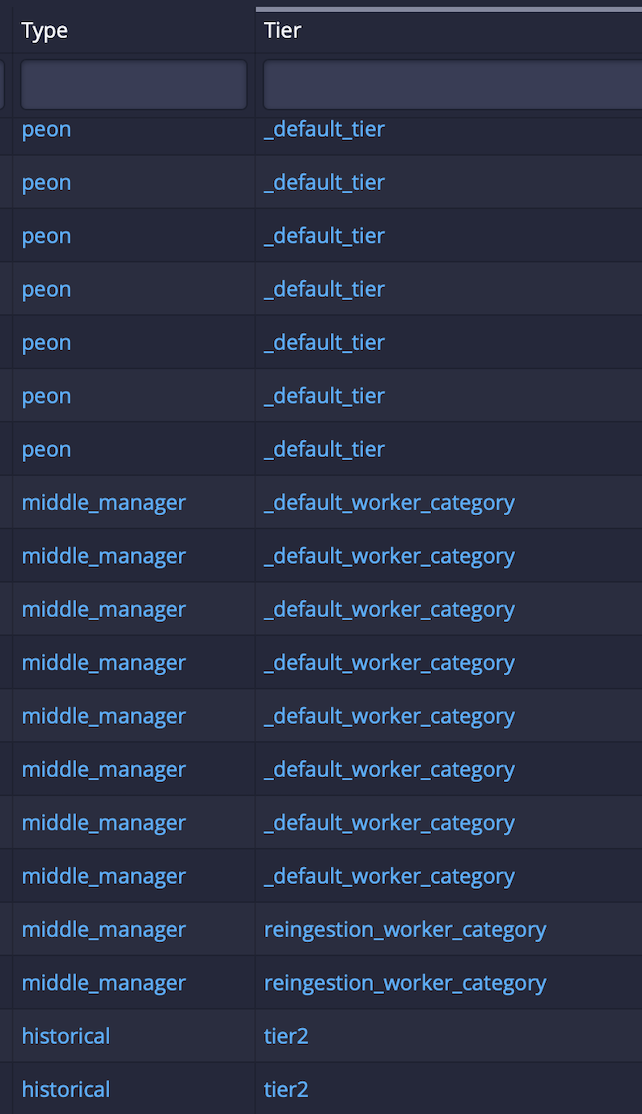
4 - After the tier2 is created with the above settings, we can go to Druid Unified Console -> Services tab to verify the new worker category of middleManager nodes in new tier.
5 - Then we can go to Druid Unified Console -> Settings -> Overlord Dynamic Config -> Select strategy to assign various types of ingestion jobs on various data sources to different categories
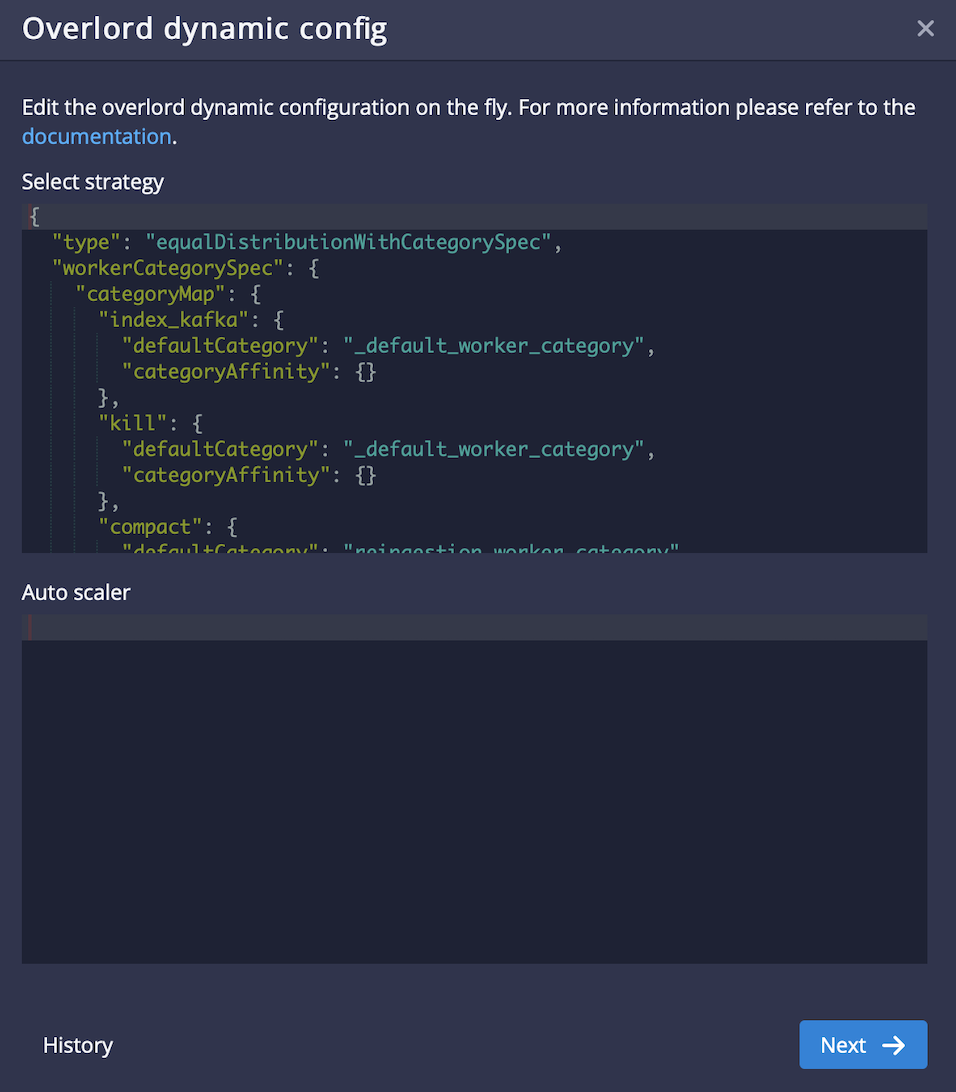
6 - Sample select strategy config based on workerCategorySpec
{
"type": "equalDistributionWithCategorySpec",
"workerCategorySpec": {
"categoryMap": {
"index_kafka": {
"defaultCategory": "_default_worker_category",
"categoryAffinity": {}
},
"kill": {
"defaultCategory": "_default_worker_category",
"categoryAffinity": {}
},
"compact": {
"defaultCategory": "reingestion_worker_category",
"categoryAffinity": {}
},
"index_parallel": {
"defaultCategory": "reingestion_worker_category",
"categoryAffinity": {
"example_datasource": "reingestion_worker_category"
}
},
"single_phase_sub_task": {
"defaultCategory": "reingestion_worker_category",
"categoryAffinity": {}
},
"partial_dimension_cardinality": {
"defaultCategory": "reingestion_worker_category",
"categoryAffinity": {}
},
"partial_index_generate": {
"defaultCategory": "reingestion_worker_category",
"categoryAffinity": {}
},
"partial_index_generic_merge": {
"defaultCategory": "reingestion_worker_category",
"categoryAffinity": {}
},
"partial_dimension_distribution": {
"defaultCategory": "reingestion_worker_category",
"categoryAffinity": {}
},
"partial_range_index_generate": {
"defaultCategory": "reingestion_worker_category",
"categoryAffinity": {}
}
},
"strong": true
}
}
REFERENCES:
Steps for Affinity - https://support.imply.io/hc/en-us/articles/360044381514
https://druid.apache.org/docs/latest/configuration/index.html