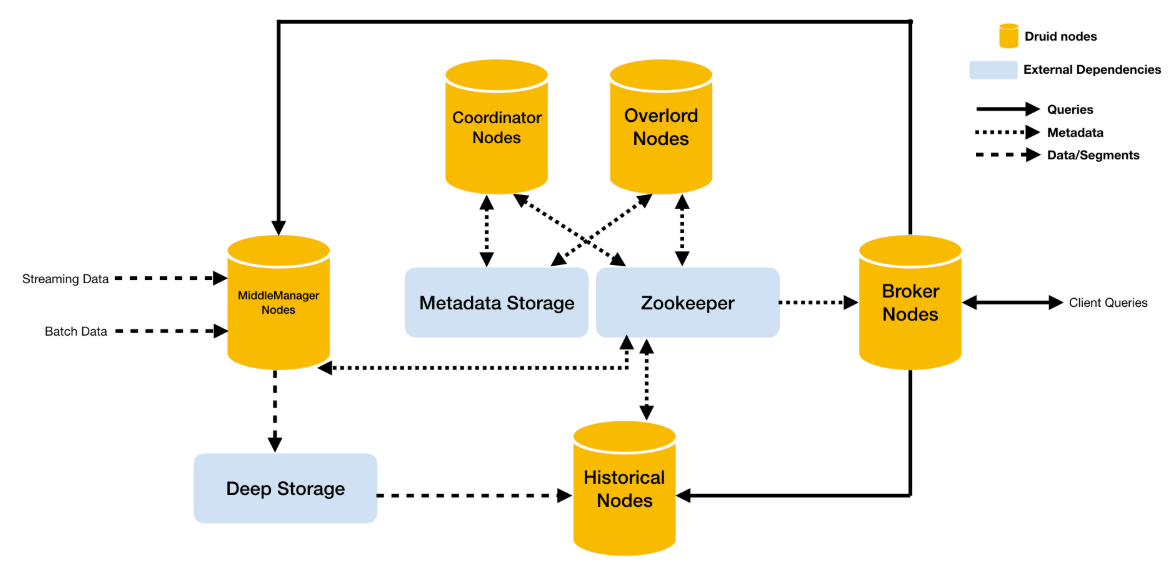
A Druid cluster can only be as stable as its Zookeeper. By design, Druid nodes are prevented from talking to each other. Zookeeper is responsible for much of the communication that keeps the Druid cluster functioning.
For maximum ZK stability, follow these best practices:
- Architecture
- Keep a dedicated ZK for Druid; avoid sharing with other products / applications
- Maintain an odd number of zookeepers. For increased reliability (high availability), use 3 or 5 ZK's so that it can maintain a quorum in voting decisions (ceiling(n/2)). Voting decisions include IP discovery, determining which overlord or coordinator is the leader, etc.
- For example, with 3 ZK's, 1 ZK can be lost and the cluster can still function because 2 are left, which = ceil(3/2). In a cluster with 2 ZK's, only 1 is needed to maintain a "quorum", so it does not provide high availability. Two ZK's doubles the probability of failure and therefore is actually less preferable than 1 ZK.
-
Imply prefers to colocate ZK on master nodes rather than data or query nodes. This is because the coordinator and overlord are normally far less work intensive than data or query nodes
-
Never put ZK behind a load balancer. This can work if all ZK servers are healthy, but if one goes down it can be difficult for the client to find a replacement. Because ZK recovery is hampered in this case, it defeats the purpose of high availability.
-
ZK Data and Log files should be on disks, which have least contention from other I/O activities. Ideally the ZK data and ZK transaction log files should be on different disks, so that they don't contend for the IO resource. Note that, it isn't enough to just have partitions but they have to be different disks to ensure performance. If possible use high speed disks like SSD's for dataDir and dataLogDir locations.
- Configuration
- List ZK IP's as hosts rather than DNS names in the common.runtime.properties. The reason for this is that there are some bugs in the part of the ZK code that handles DNS mappings, including one where ZK won't retry the connection if DNS becomes unavailable.
Example common.runtime.properties:
druid.zk.service.host=172.16.xxx.x1,172.16.xxx.x2,172.16.xxx.x3
- When running in HA mode, add all ZK server IP's to zoo.cfg to ensure that ZK can properly elect its own leader:
...
#
# Ensemble
#
server.1=172.16.xxx.x1:2888:3888
server.2=172.16.xxx.x2:2888:3888
server.3=172.16.xxx.x3:2888:3888 - In the dataDir for the respective ZK servers, ensure that the myid file has the same number as defined by server.x in the above. For example, if dataDir is defined as /opt/imply-2.8.7/var/zk, on server.1, myid file should have an entry of 1. In case of server.2, it should be 2. This can be verified by doing a cat /opt/imply-2.8.7/var/zk/myid on server.1 (172.16.xxx.x1)
- Try to keep the Zookeeper log transaction and data dir to be in independent disks. These can be defined in zoo.cfg using dataDir and dataLogDir parameters.
- In ZK version 3.4.0 and above, enable auto purging of transaction logs using autopurge.purgeInterval=1 in zoo.cfg. This would ensure that the older transaction logs are cleaned up regularly and avoids disk full situations. By default 3 transaction logs are retained and this is controlled by autopurge.snapRetainCount in zoo.cfg.
- All ZK servers should use the same configuration
- List ZK IP's as hosts rather than DNS names in the common.runtime.properties. The reason for this is that there are some bugs in the part of the ZK code that handles DNS mappings, including one where ZK won't retry the connection if DNS becomes unavailable.
Refer to ZK Documentation for more information.