Objective:
Step by step guide to configure Druid to run Hadoop ingestion with Google Cloud Platform.
Step 1: Login to GCP console:
Go to GCP console page https://console.cloud.google.com/, and log in with your credential.
Step 2: Create a service account that will access the bucket:
Browse to "IAM & Admin" -> "Service Accounts" -> "Create Service Account", Create a service account, in this example "imply-cs"
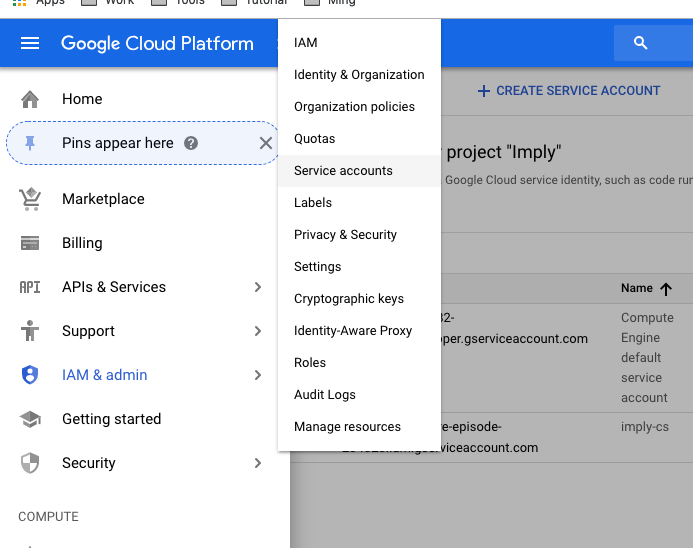
At permission section of the "imply-cs", make sure your user name is listed as one of the owners
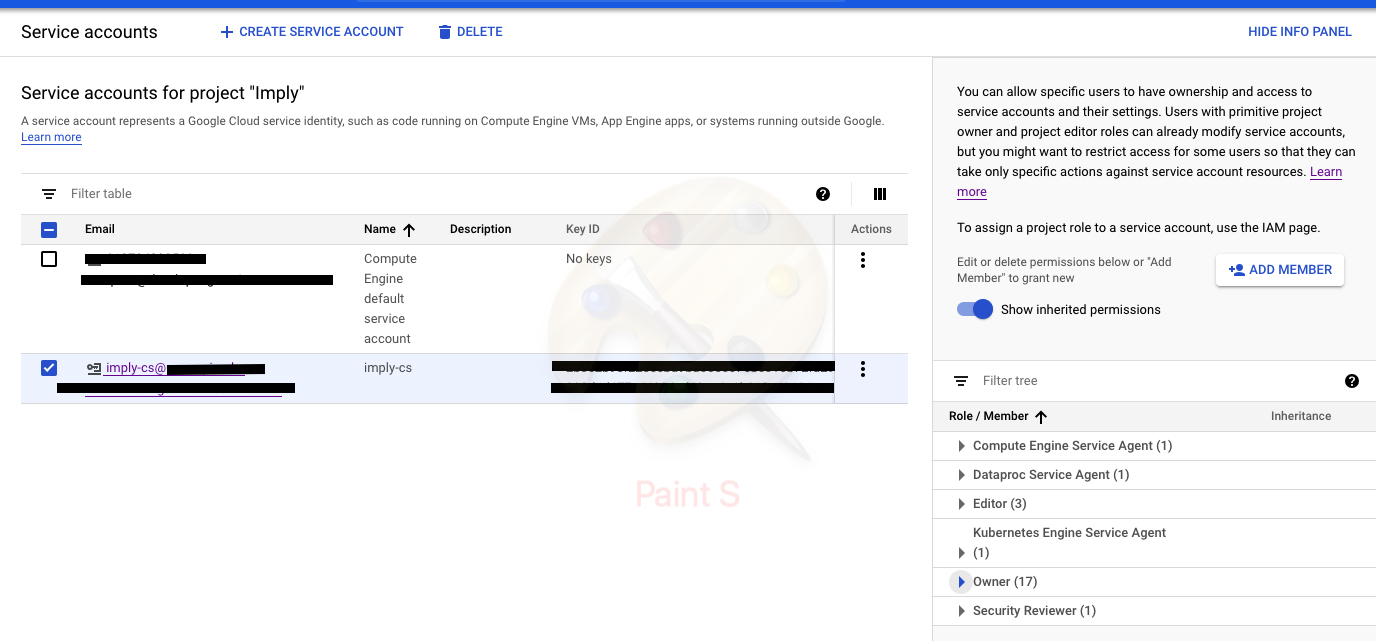
Click on "Create key"
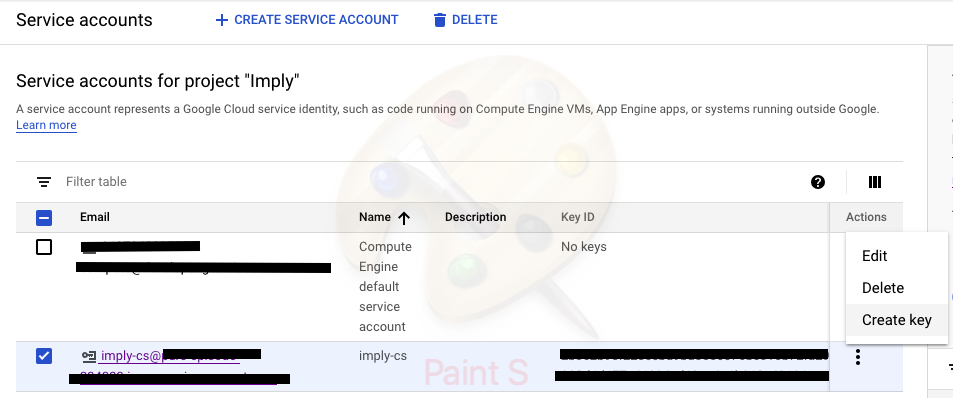

Download the JSON file that created, and save for later use. That's the authentication/authorization credential for your Druid hosts to access GCP.
Step 3: Apply the bucket access permission to the service account just created:
Browse to your GCP bucket through Google navigation menu -> storage -> browser -> YOUR BUCKET ("cs-bucket1" in this example)
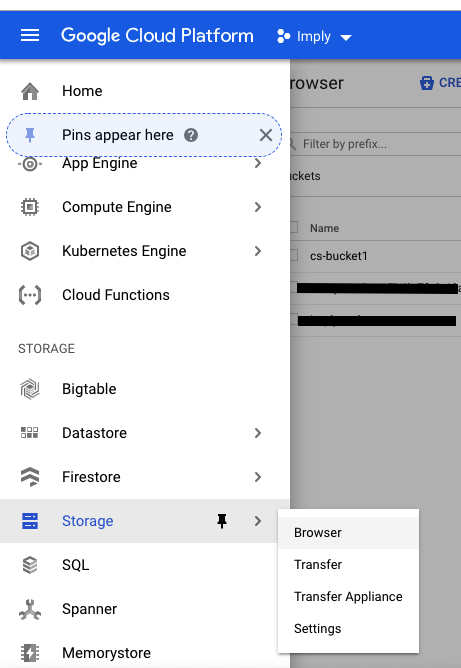
Configure user access permission on the bucket
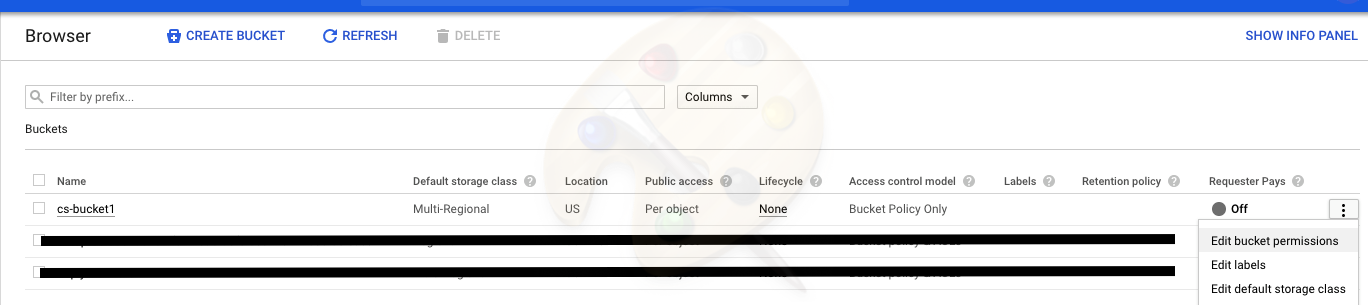
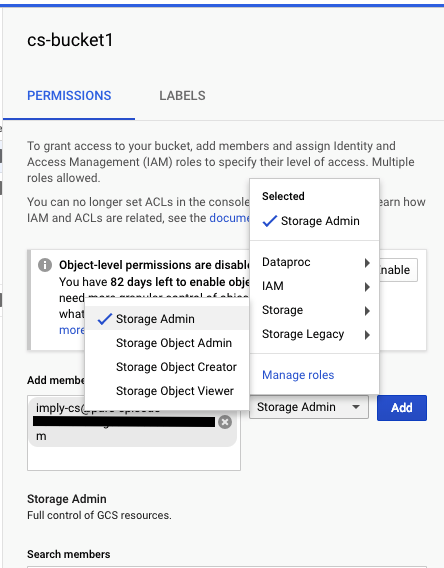
Add the service account as Storage Admin to this bucket.
Step 4: Configure environmental variable on all Druid hosts
Open SSH sessions to all druid hosts, and save the JSON file downloaded in step 2 to Imply Druid's conf (./conf) directory on all hosts. Then in your bash properties file, e.g, '~/.bash_properties' on RHEL/CentOS, create a new environment variable GOOGLE_APPLICATION_CREDENTIALS. Replace [PATH] with the file path of the JSON file that contains your service account key, and [FILE_NAME] with the filename. For example:
[root@ip-172-31-2-115 ec2-user]# cat ~/.bash_profile # .bash_profile export GOOGLE_APPLICATION_CREDENTIALS="/imply-<VERSION>/conf/googleauth.json"
[root@ip-172-31-2-115 ec2-user]# cat /imply-<VERSION>/conf/googleauth.json
{
"type": "service_account",
"project_id": "<ID>",
"private_key_id": "<KEY_ID>",
"private_key": "-----BEGIN PRIVATE KEY-----<KEY>-----END PRIVATE KEY-----\n",
"client_email": "imply-cs@<ID>.iam.gserviceaccount.com",
"client_id": "<CLIENT_ID>",
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
"token_uri": "https://oauth2.googleapis.com/token",
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url": "<URL>"
}
Step 5: Add "Druid-google-extensions" to the Druid's "druid.extensions.loadList" in the Druid's "common.running.properties".
Step 6: Add following to replace the current deep storage config in "common.running.properties"
druid.storage.type=google druid.google.bucket=cs-bucket1 druid.google.prefix=druid/segments
Step 7: Add following to replace the current index logging config in "common.running.properties"
druid.indexer.logs.type=google druid.indexer.logs.bucket=cs-bucket1 druid.indexer.logs.prefix=druid/indexing-logs
Step 8: Download the gcs connector driver, and place it to both Druid's lib and "druid-google-extension" directories
wget https://storage.googleapis.com/hadoop-lib/gcs/gcs-connector-hadoop2-latest.jar /imply-2.8.17/dist/druid/extensions/druid-google-extensions/ /imply-2.8.17/dist/druid/lib/
Step 9: Configure the Hadoop to interact with GCP
Copy the same "googleauth.json" in step 4 to "/etc/hadoop/conf" directory on all Hadoop hosts.
Change the file permission to 444
Add following config to "core-site.xml" file on all Hadoop hosts
fs.gs.auth.service.account.json.keyfile=/etc/hadoop/conf/googleauth.json fs.gs.working.dir=/ fs.gs.path.encoding=uri-path fs.gs.reported.permissions=777
Restart Hadoop cluster.
Test GCP access using HDFS client
hadoop fs -ls gs://cs-bucket1/
Step 10: Copy the latest "core-site.xml" to /imply-<VERSION>/conf/druid/_common directory on all Druid hosts.
Restart Druid cluster.
Step 11: Upload test raw data JSON file "wikipedia-2016-06-27-sampled.json" to GCP bucket "cs-bucket1"
Step 12: Run Hadoop ORC ingestion using following spec:
{
"type" : "index_hadoop",
"spec" : {
"dataSchema" : {
"dataSource" : "wikipedia-hadoop",
"parser" : {
"type" : "hadoopyString",
"parseSpec" : {
"format" : "json",
"dimensionsSpec" : {
"dimensions" : [ "channel", "cityName", "comment", "countryIsoCode", "countryName", "isAnonymous", "isMinor", "isNew", "isRobot", "isUnpatrolled", "metroCode", "namespace", "page", "regionIsoCode", "regionName", "user", {
"name" : "commentLength",
"type" : "long"
}, {
"name" : "deltaBucket",
"type" : "long"
}, "flags", "diffUrl", {
"name" : "added",
"type" : "long"
}, {
"name" : "deleted",
"type" : "long"
}, {
"name" : "delta",
"type" : "long"
} ]
},
"timestampSpec" : {
"column" : "timestamp",
"format" : "iso"
}
}
},
"metricsSpec" : [ ],
"granularitySpec" : {
"type" : "uniform",
"segmentGranularity" : "DAY",
"queryGranularity" : {
"type" : "none"
},
"rollup" : false,
"intervals" : [ "2016-06-20T00:00:00.000Z/2016-07-02T00:00:00.000Z" ]
},
"transformSpec" : {
"filter" : null,
"transforms" : [ ]
}
},
"ioConfig" : {
"type" : "hadoop",
"inputSpec" : {
"type" : "static",
"paths" : "gs://cs-bucket1/wikipedia-2016-06-27-sampled.json"
},
"metadataUpdateSpec" : null,
"segmentOutputPath" : null
},
"tuningConfig" : {
"type" : "hadoop",
"workingPath" : null,
"partitionsSpec" : {
"type" : "hashed",
"targetPartitionSize" : 5000000,
"maxPartitionSize" : 7500000,
"assumeGrouped" : false,
"numShards" : -1,
"partitionDimensions" : [ ]
},
"shardSpecs" : { },
"indexSpec" : {
"bitmap" : {
"type" : "concise"
},
"dimensionCompression" : "lz4",
"metricCompression" : "lz4",
"longEncoding" : "longs"
},
"maxRowsInMemory" : 1000000,
"maxBytesInMemory" : 0,
"leaveIntermediate" : false,
"cleanupOnFailure" : true,
"overwriteFiles" : false,
"ignoreInvalidRows" : false,
"jobProperties" : {
"mapreduce.job.user.classpath.first" : "true",
"mapreduce.map.java.opts" : "-Duser.timezone=UTC -Dfile.encoding=UTF-8",
"mapreduce.reduce.java.opts" : "-Duser.timezone=UTC -Dfile.encoding=UTF-8"
},
"combineText" : false,
"useCombiner" : false,
"buildV9Directly" : true,
"numBackgroundPersistThreads" : 0,
"forceExtendableShardSpecs" : true,
"useExplicitVersion" : false,
"allowedHadoopPrefix" : [ ],
"logParseExceptions" : false,
"maxParseExceptions" : 0
}
},
"hadoopDependencyCoordinates" : null,
"classpathPrefix" : null,
"context" : { },
"dataSource" : "wikipedia-hadoop"
}