The unified Druid Console was introduced in Imply 2.9 / Druid 0.14. This console is based on API calls to system schema tables, which were introduced in Druid 0.13.
In a cluster with a large number of segments (~1 million) and/or large number of datasources, the current Druid console response can be less than snappy. There are a few improvements in the works to address this. There are two things that can be done at the moment:
1. Set druid.sql.planner.metadataSegmentCacheEnable=true in the broker runtime.properties. Please note this setting will create more memory pressure on the brokers, so should be tested in a staging environment first.
2. Upgrade:
- Imply 3.4 / Druid 0.19 includes PR #9883 to remove the payload from sys.segments table
- Imply 2021.04 includes PR #10909 to query only columns in view in Datasources & Segments tabs
- Imply 2021.04 includes PR #11008 to make hash computes and authorization more efficient
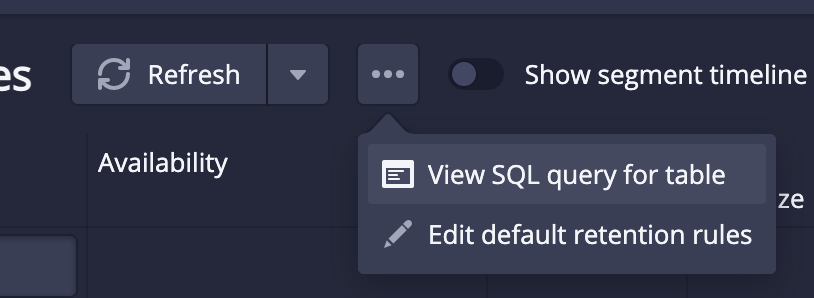
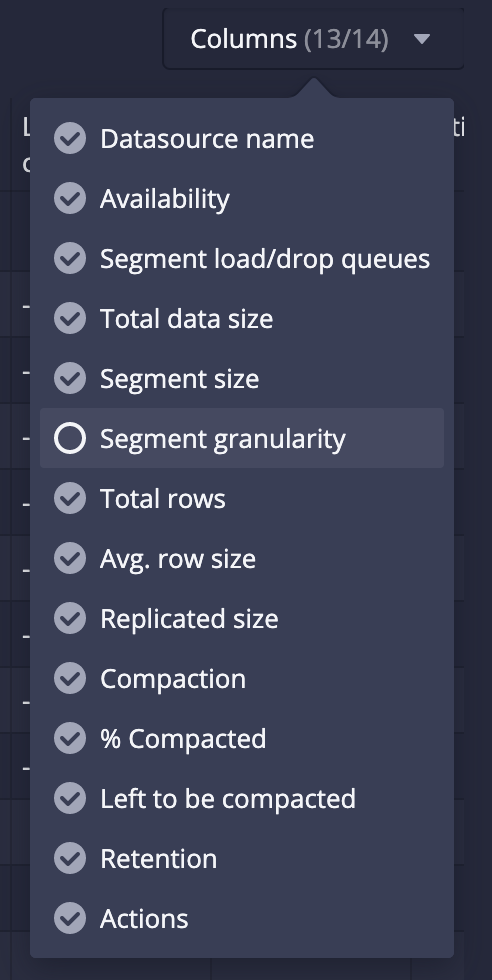
3. In the Datasources tab, hide the "Segment granularity" column. This column uses LIKE operators, which can slow loading. This can be verified by the "View SQL query for table" button:
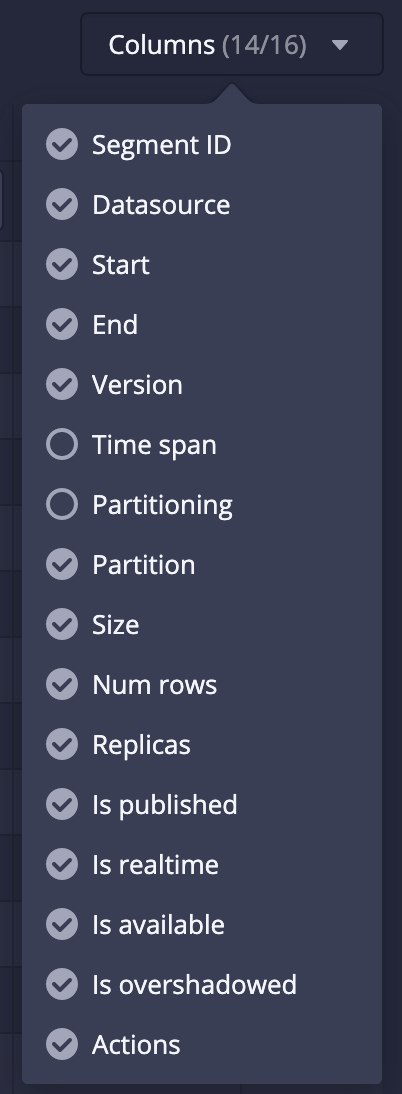
4. In the Segments tab, hide "Time span" and "Partitioning". These columns also utilize LIKE operators.
If the above don't improve the loading time of the console to acceptable levels, there is a fallback option to allow the Datasources tab of the console to function on coordinator APIs and the Ingestion tab to function on the overlord APIs instead of the sys tables:
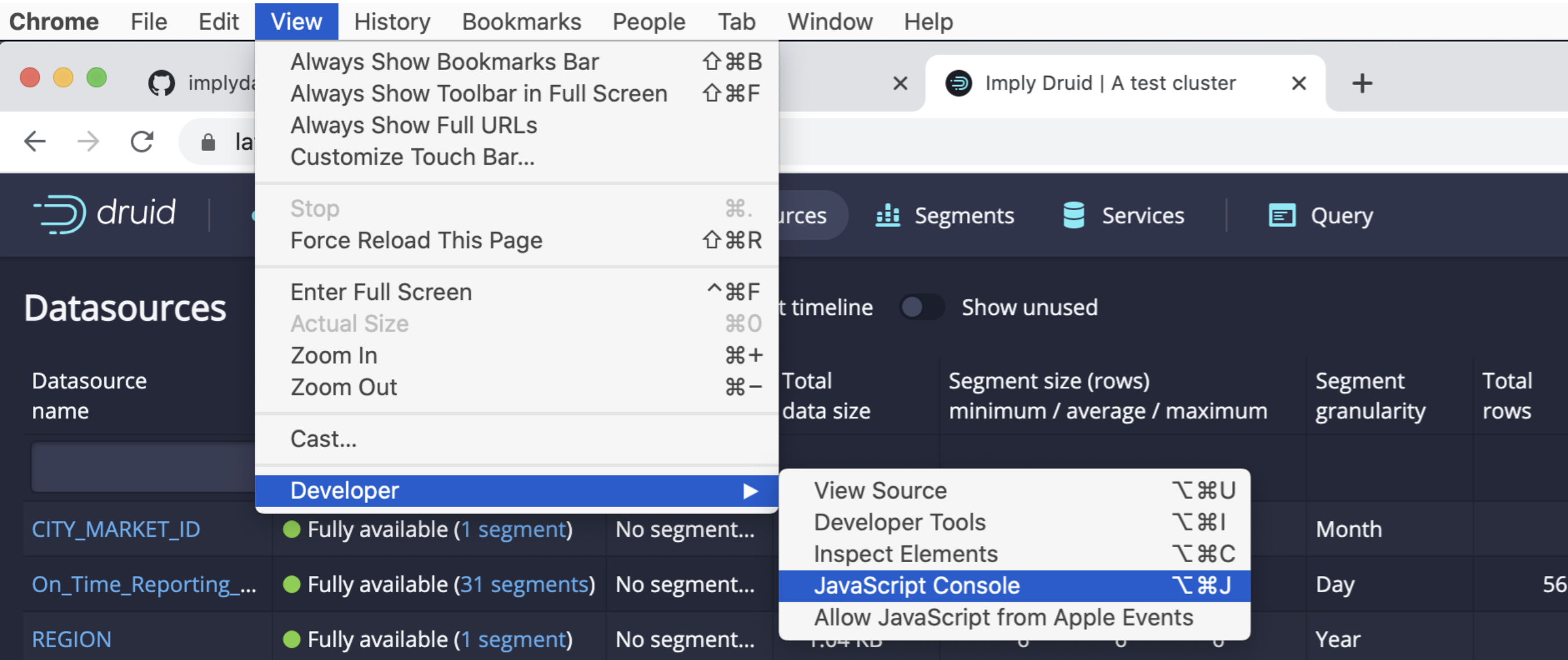
1. In the Druid console, open the JavaScript dev console:
2. In the JS console, run the command:
localStorage.setItem('capabilities-override', '{"queryType":"none","coordinator":true,"overlord":true}');localStorage.setItem('segments-refresh-rate',0);location.reload()
The console will reload and run in coordinator mode until removed via the command below or by 'clearing stored data') in the browser.
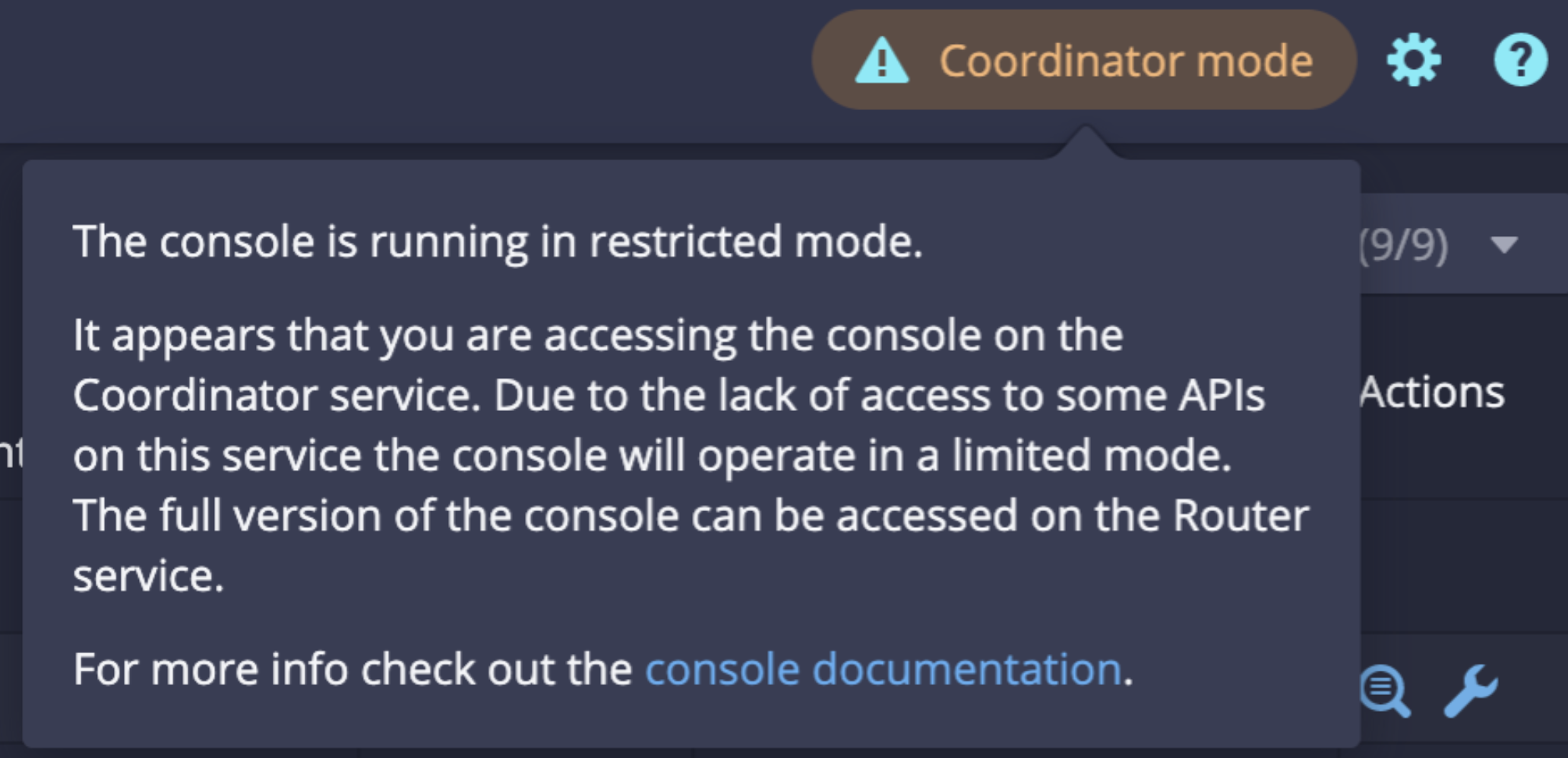
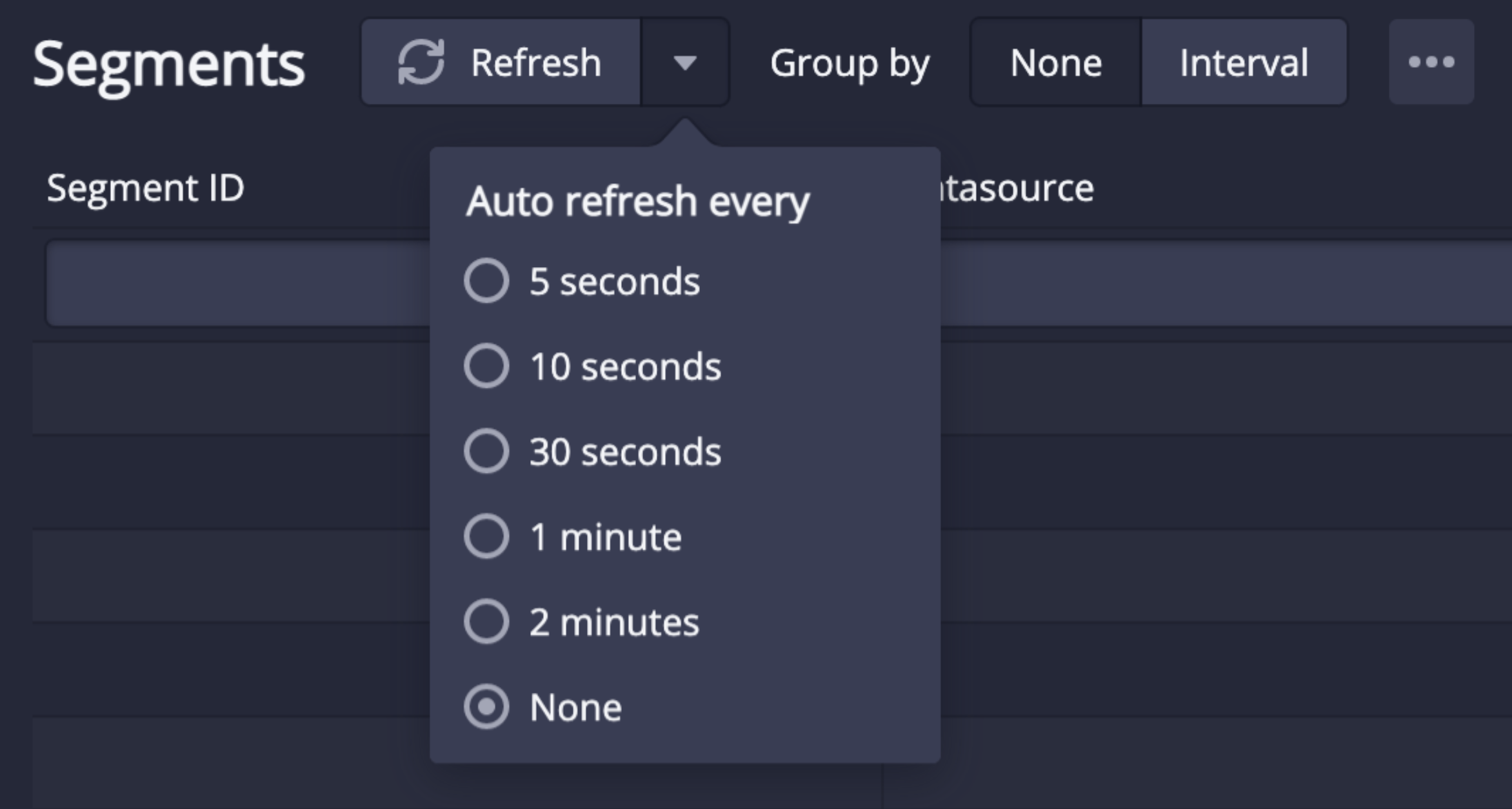
The command above will also disable the auto-refresh in the Segments tab, which will still be running on the sys.segments table:
**Note that the "Load Data" and "Query" tabs will not be available in this mode.
3. To undo, run this command in the JS console:
localStorage.removeItem('capabilities-override');localStorage.removeItem('segments-refresh-rate');location.reload()